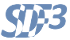
Synchronous Dataflow
Graph transformations
This section explains the various graph transformation algorithms that are implemented in SDF3.
Limit auto-concurrency
| Tool | sdf3transform-sdf --transform 'model_autoconc(<max>)' |
|---|---|
| API | modelAutoConcurrencyInSDFgraph() |
The SDF Model-of-Computation assumes that infinitly many compute resources are available. Using this assumption, it allows multiple simultanious firings of the same actor (i.e. it allows auto-concurrency). Auto-concurrency can be limited by adding self-edges to actors.
In this example, the auto-concurrency of the actors is limited to 3. This means that only three instances of each actor can be firing simultaneously.
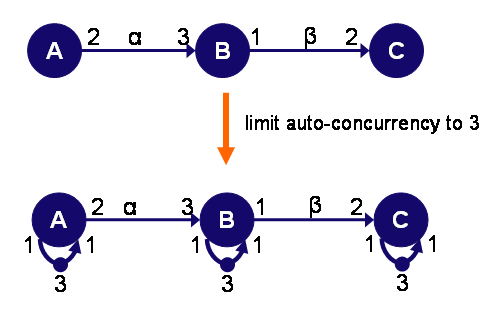
Model storage-space constraints
| Tool | sdf3transform-sdf --transform 'model_buffersize' |
|---|---|
| API | modelBufferSizeInSDFgraph() |
Back-edges can be used to model storage-space constraints on the channels of an SDFG. SDF3 can automatically add these back-edges to an SDFG when storage constrains are available for the channels of this SDFG.
In this example, the storage space of the channels alpha and beta is limited to respectively 4 and 2 tokens. The constraint on the first channel (alpha) is modeled with a back-edge from actor B to actor A that contains initially 4 tokens.
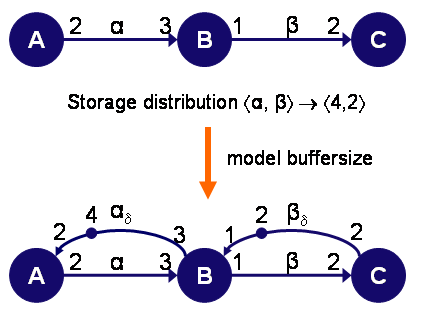
SDFG to HSDFG conversion
| Tool | sdf3transform-sdf --transform 'to_hsdf' |
|---|---|
| API | transformSDFtoHSDF() |
Any SDFG can be converted to a correpsonding HSDFG in which all rates are equal to one. This is done using an algorithm described by Sriram and Bhattacharyya in "Embedded Multiprocessors Scheduling and Synchronization" (Marcel Dekker, 2000). Note that the conversion can lead to an exponential increase in the number of actors in the HSDFG. The number of actors in the resulting HSDFG depends on the entries of the actors in the repetition vector.
Unfolding
| Tool | sdf3transform-sdf --transform 'unfold(<count>)' |
|---|---|
| API | unfoldHSDF() |
Unfolding of an SDFG creates additional scheduling freedom. Unfolding requires first a transformation of the SDFG to an HSDFG. After that, all actors are copied as often as required for the unfolding and the sequence edges between the actor copies are constructed such that all inherent dependencies between the actor firings are respected.
In this example, the SDFG is unfolded one time. This enables scheduling algorithms to schedule more copies of actor A before scheduling actor B. For some graphs, this may allow schedules which can achieve a higher throughput. This is especially usefull for blocking schedules.
